Submitted by AmirhoseinGH 48 Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits University of Alberta 6 3
Submitted by leo1117 45 NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation ByteDance 60 2
Submitted by XuGuo699 34 DreamID-V:Bridging the Image-to-Video Gap for High-Fidelity Face Swapping via Diffusion Transformer ByteDance 86 3
Submitted by leo1117 28 VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation ByteDance 2
Submitted by haoranhe 23 GARDO: Reinforcing Diffusion Models without Reward Hacking · 10 authors 18 3
Submitted by taesiri 22 VINO: A Unified Visual Generator with Interleaved OmniModal Context · 6 authors 42 2
Submitted by yantaiyang05 21 InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams AutoLab 76 2
Submitted by taesiri 13 Falcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling Technology Innovation Institute 1
Submitted by taesiri 11 Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes · 9 authors 13 1
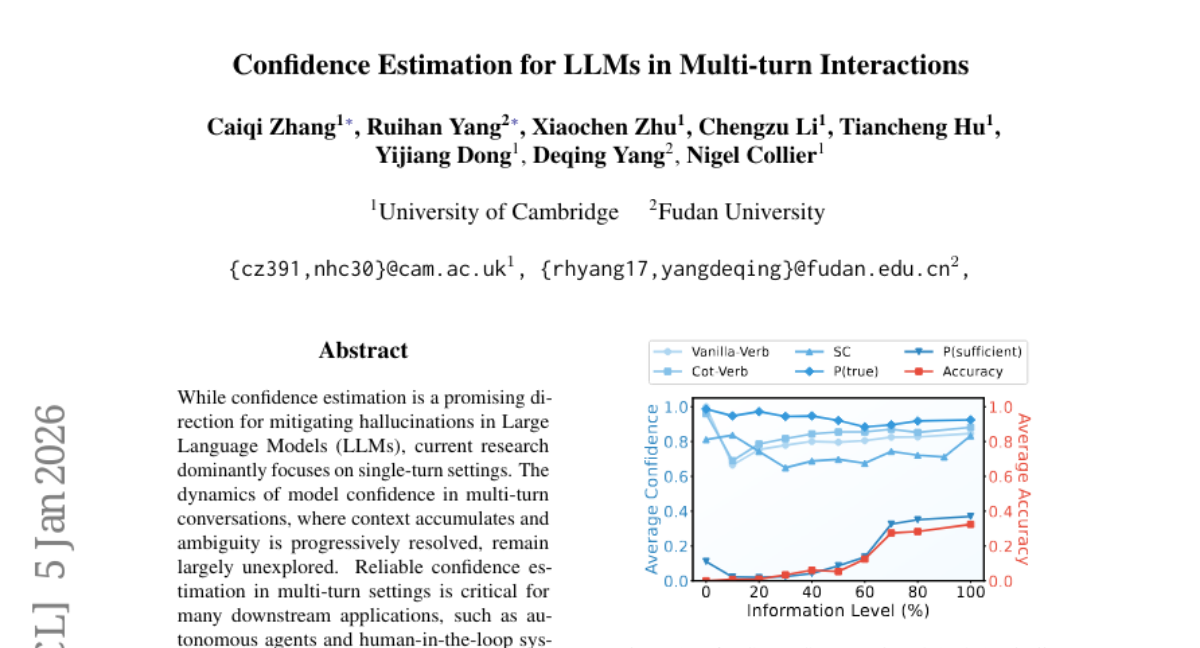
Submitted by caiqizh 7 Confidence Estimation for LLMs in Multi-turn Interactions University of Cambridge 2
Submitted by yixuantt 5 KV-Embedding: Training-free Text Embedding via Internal KV Re-routing in Decoder-only LLMs · 2 authors 2
Submitted by AhNr 5 CPPO: Contrastive Perception for Vision Language Policy Optimization · 9 authors 3
Submitted by wrk226 4 DiffProxy: Multi-View Human Mesh Recovery via Diffusion-Generated Dense Proxies · 4 authors 1 2
Submitted by oneonlee 4 COMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in LLMs AIM Intelligence 8 2
Submitted by YuxinJiang 4 SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving SWE-Lego 8 3
Submitted by XavierJiezou 4 Toward Stable Semi-Supervised Remote Sensing Segmentation via Co-Guidance and Co-Fusion · 10 authors 4 3
Submitted by taesiri 1 OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment · 23 authors 3 1
Submitted by mjbuehler 1 Selective Imperfection as a Generative Framework for Analysis, Creativity and Discovery LAMM: MIT Laboratory for Atomistic and Molecular Mechanics 2 3
Submitted by kabhishe 1 IMA++: ISIC Archive Multi-Annotator Dermoscopic Skin Lesion Segmentation Dataset Medical Image Analysis Lab, SFU 0 3
Submitted by lalitmaurya47 - Prithvi-Complimentary Adaptive Fusion Encoder (CAFE): unlocking full-potential for flood inundation mapping · 3 authors 3 2
Submitted by Suren15 - Project Ariadne: A Structural Causal Framework for Auditing Faithfulness in LLM Agents Toronto Metropolitan University 2 2
Submitted by jwliao1209 - M-ErasureBench: A Comprehensive Multimodal Evaluation Benchmark for Concept Erasure in Diffusion Models · 4 authors 3


 AmirhoseinGH
AmirhoseinGH