
ROMA: Real-time Omni-Multimodal Assistant with Interactive Streaming Understanding
Paper
•
2601.10323
•
Published
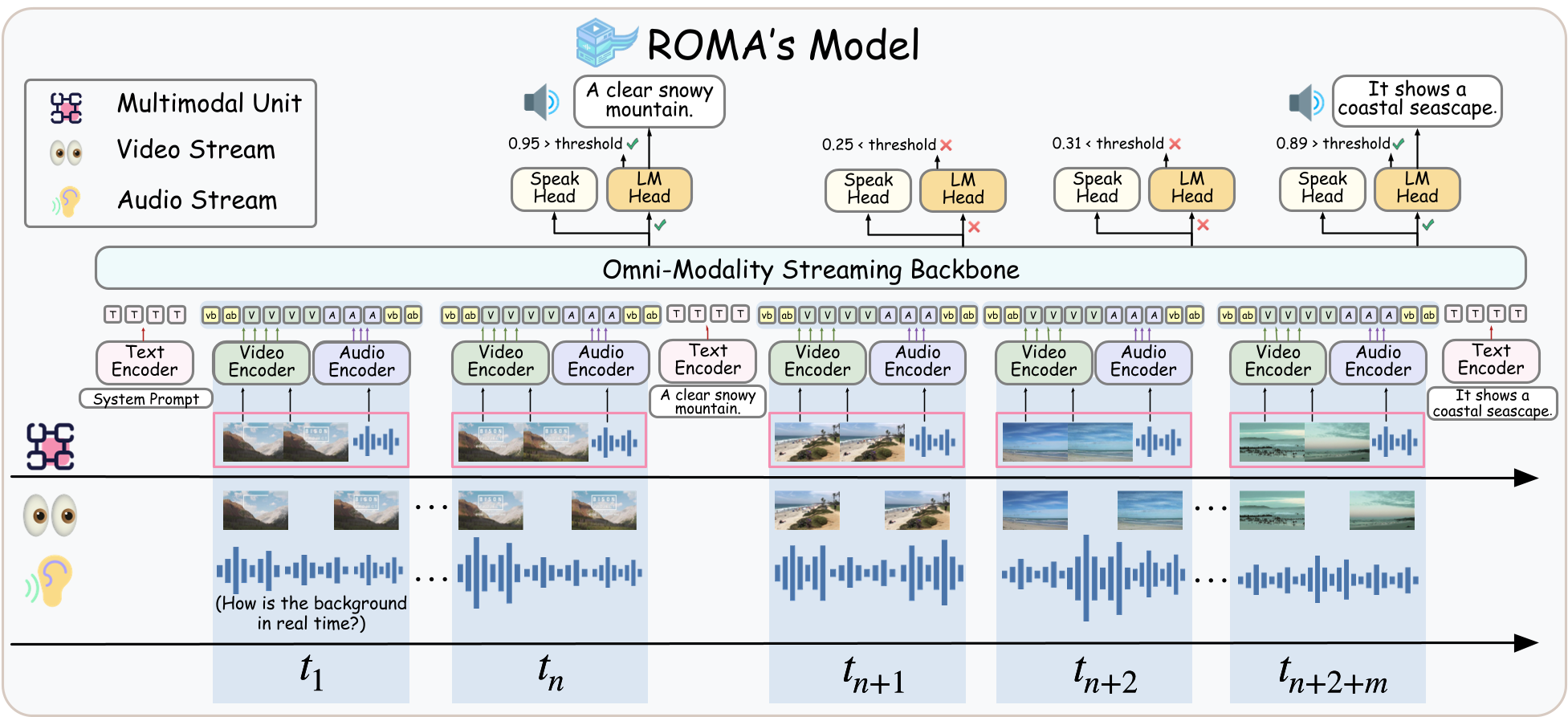
Figure: ROMA processes streaming inputs as aligned multimodal units, using a 'Speak Head' to decide when to respond.
ROMA is a Real-time Omni-Multimodal Assistant designed for unified streaming audio-video understanding. Unlike traditional videoLLMs that only answer after a query, ROMA integrates both Reactive (Question Answering) and Proactive (Event-Driven Alert, Real-Time Narration) capabilities within a single framework.
ROMA introduces a "Speak Head" mechanism to decouple response timing from content generation, allowing it to autonomously decide when to speak based on the continuous audio-visual stream.
If you find this project useful, please cite:
@article{tian2026roma,
title={ROMA: Real-time Omni-Multimodal Assistant with Interactive Streaming Understanding},
author={Tian, Xueyun and Li, Wei and Xu, Bingbing and Dong, Heng and Wang, Yuanzhuo and Shen, Huawei},
journal={arXiv preprint arXiv:2601.10323},
year={2026}
}