
license: cc-by-4.0
language:
- en
tags:
- Emotion
- Morality
- Events
pretty_name: E2MoCase
size_categories:
- 10K<n<100K
configs:
- config_name: bert-base-uncased
data_files: data/bert-base-uncased/*.parquet
default: true
- config_name: all-MiniLM-L6-v2
data_files: data/all-MiniLM-L6-v2/*.parquet
- config_name: all-mpnet-base-v2
data_files: data/all-mpnet-base-v2/*.parquet
- config_name: Qwen3-Embedding-0.6B
data_files: data/Qwen3-Embedding-0.6B/*.parquet
- config_name: BAAI-bge-m3
data_files: data/BAAI-bge-m3/*.parquet
E2MoCase: summary
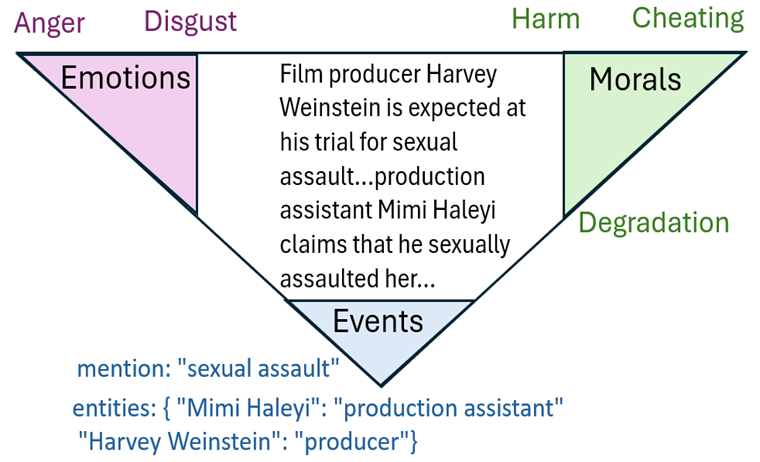
E2MoCase is a novel curated dataset linking news stories about real-world legal cases to (i) the concrete events they describe, (ii) the emotions they evoke, and (iii) the moral foundations they frame. Articles are segmented into paragraphs, and each paragraph is independently annotated with aligned event (triggering words and involved entities), emotion labels, and moral labels, giving researchers a fine-grained lens on narrative bias. The resource paper describing the dataset is currently under review at CIKM 2025.
Data access and reproducibility
The source articles for E2MoCase were retrieved through Swissdox@LiRI platform. The raw news paragraphs cannot be openly shared due to commercial restrictions imposed by Swissdox. However, the original query (in YAML format) used for retrieving data from Swissdox@LiRI can be found in our Github repository. Additionally, aggregated/derived data can also be made available: here we release the sentence embedding of the source paragraphs, generated with various pretrained language models (e.g., bert-base-uncased, Qwen3-0.6B), along with their annotations (see the Data Description Section for further details). We also release the source code for rebuilding the dataset from scratch, including the interface to SwissDoc library in our Github repository.
We are continuously refining and expanding the E2moCase dataset. Stay tuned for upcoming updates!
Data Description
E2MoCase contains 97,251 paragraphs extracted from a total of 19,250 news articles. These news articles were obtained from about 100 candidate real-world cases related to legal matters that had significant media impact due to evidence of cultural biases, such as religious, political, gender, racial, and media biases. For each case, we manually verified its factual accuracy, we ensured it had significant media impact and it was covered by reputable newspaper agencies.
All paragraphs are labeled with emotions and moralities. Of these, 50,975 paragraphs are also labeled with events, whereas the remaining ones do not contain events. The statistics of E2MoCase and its variants are shown as follows.
| E2MoCase | E2MoCase_noEvents | E2MoCase_full | |
|---|---|---|---|
| # paragraphs | 50,975 | 46,276 | 97,251 |
| avg # tokens | 275.106 ± 245.303 | 139.402 ± 220.950 | 210.532 ± 243.647 |
| avg # emotions | 1.164 ± 0.757 | 1.634 ± 0.680 | 1.678 ± 0.657 |
| avg # morals | 3.517 ± 3.870 | 1.773 ± 1.644 | 2.795 ± 2.424 |
| avg # events | 3.597 ± 2.940 | 0.0 ± 0.0 | 1.885 ± 2.785 |
E2MoCase_noEvents, is the dataset obtained by removing paragraphs that do not contain events, while E2MoCase_full, is the version that also includes paragraphs that do not contain events.
The dataset contains the following fields:
content_id: Identification code of the news item within SwissDox.P: Paragraph identification code. It takes the form $P_i$, where $i$ is the $i$-th paragraph within the news item.subject: Main subject of the news item (e.g., Julia Rossi case, Harvey Weinstein case).event: List of events in JSON formatcare,harm,fairness,cheating,loyalty,betrayal,authority,subversion,purity,degradation: Real-valued scores (within 0 and 1) associated with moral valuesanticipation,trust,disgust,joy,optimism,surprise,love,anger,sadness,pessimism,fear: Real-valued scores (within 0 and 1) associated with emotion valuesembeddings: Paragraph-level embeddins computed with different SentenceTransformers (e.g., bert-base uncased, Qwen3-0.6B)
Example data
Given the following paragraph:
"Mystery without an answer: Where is Sarah's murderer?
Julia Rossi was acquitted of murdering Sarah Bianchi.
But if it wasn't her, then who killed the Italian woman with 25 stab wounds?"
An annotated data instance associated with the paragraph is as follows:
event:
[
{"mention": "murder", "entities": {"Julia Rossi": "murderer", "Sarah Bianchi": "victim"}},
{"mention": "kill", "entities": {"Julia Rossi": "murderer", "Sarah Bianchi": "victim"}}
]
Moral columns:
| care | harm | fairness | cheating | loyalty | betrayal | authority | subversion | purity | degradation |
|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 0.985 | 0.0 | 0.901 | 0.0 | 0.910 | 0.0 | 0.0 | 0.0 | 0.221 |
Emotion columns:
| anticipation | trust | disgust | joy | optimism | surprise | love | anger | sadness | pessimism | fear |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 0.0 | 0.521 | 0.0 | 0.0 | 0.0 | 0.0 | 0.5 | 0.0 | 0.0 | 0.0 |
embeddings (BERT):
[
-0.03578636795282364, -0.1418502777814865, -0.057445134967565536, 0.33489108085632324,
-0.4916315972805023, 0.14585624635219574, 0.5827698707580566, 0.10768894851207733,
0.1799188107252121, -0.1422875076532364, 0.32683268189430237, -0.03329094871878624,
-0.12012719362974167, -0.11901112645864487, 0.2651849389076233, 0.23091290891170502,
0.1272478997707367, 0.5687066316604614,
…
]
Note: in the above example, all references to real persons have been replaced with fictitious names..
Data usage
import pandas as pd
from datasets import load_dataset
import ast
moral_columns = ['care', 'harm', 'fairness', 'cheating', 'loyalty', 'betrayal', 'authority', 'subversion', 'purity',
'degradation']
emotion_columns= [
'anticipation', 'trust', 'disgust', 'joy', 'optimism', 'surprise',
'love', 'anger', 'sadness', 'pessimism', 'fear']
ds = load_dataset('lorenzozan/E2MoCase', split='train') # load the base version
print(ds)
"""
Dataset({
features: ['content_id', 'P', 'event', 'subject', 'care', 'harm', 'fairness', 'cheating', 'loyalty', 'betrayal', 'authority', 'subversion', 'purity', 'degradation', 'anticipation', 'trust', 'disgust', 'joy', 'optimism', 'surprise', 'love', 'anger', 'sadness', 'pessimism', 'fear', 'embeddings'],
num_rows: 97251
})
"""
df = ds.to_pandas() # convert to pandas
# Print 5 random rows
df = ds.to_pandas().sample(frac=1)
df[['subject']+emotion_columns+moral_columns].head(5)
print(df['embeddings'][1].shape) # 768
df['event'] = df['event'].apply(ast.literal_eval)
print(df['event'])
You can also download the dataset with sentence embeddings provided by other pre-trained language models, e.g., Qwen-3-Embedding-0.6B:
from datasets import get_dataset_config_names
ds = load_dataset('lorenzozan/E2MoCase', 'Qwen3-Embedding-0.6B', split='train')
configs = get_dataset_config_names("lorenzozan/E2MoCase")
print(configs) # all availabel configs
"""
['bert-base-uncased', 'all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'Qwen3-Embedding-0.6B', 'BAAI-bge-m3']
"""
Currently, the available sentence embeddings are all-mpnet-base-v2, all-MiniLM-L6-v2, bert-base-uncased, Qwen3-Embedding-0.6B and BAAI/bge-m3.
Ethical use of data and informed constent
This data repository is made available for research purposes only.
E2MoCase includes biased news due to its case collection process. Our case selection was not influenced by the the authors' thoughts or beliefs, but was made solely for research purposes to include prominent cases with high-impact media case.
The authors are not responsible for any harm or liabilities that may arise from the propagation of such biases through downstream machine-learning models. Users should avoid deploying systems that might reinforce harmful stereotypes or discriminatory patterns.
References
The resource paper describing the dataset is currently under review at CIKM 2025.
If you use this resource, please cite:
@misc{candida_maria_greco_2025,
author = { Candida Maria Greco and Lorenzo Zangari and Davide Picca and Andrea Tagarelli },
title = { E2MoCase (Revision 745e678) },
year = 2025,
url = { https://huggingface.co/datasets/lorenzozan/E2MoCase },
doi = { 10.57967/hf/5819 },
publisher = { Hugging Face }
}
You can also refer to the following preprint (dated 2024):
@article{greco2024e2mocase,
title={E2MoCase: A Dataset for Emotional, Event and Moral Observations in News Articles on High-impact Legal Cases},
author={Greco, Candida M and Zangari, Lorenzo and Picca, Davide and Tagarelli, Andrea},
journal={arXiv preprint arXiv:2409.09001},
year={2024}
}
Also you might refer to the following paper on the topic:
@inproceedings{zangari2025me2,
title={ME2-BERT: Are Events and Emotions what you need for Moral Foundation Prediction?},
author={Zangari, Lorenzo and Greco, Candida M and Picca, Davide and Tagarelli, Andrea},
booktitle={Proceedings of the 31st International Conference on Computational Linguistics},
pages={9516--9532},
year={2025}
}